迁移大型网站总是令人望而生畏。许多移动部件、技术挑战和利益相关者管理都关系到巨大的流量。
从历史上看,迁移计划中最繁重的任务之一是重定向映射。将当前网站上的 URL 与新网站上的等效版本进行匹配是一个艰苦的过程。
幸运的是,这项任务以前可能需要多个团队仔细检查数千个 URL,而现代 AI 模型可以大大加快这一速度。
您是否应该使用人工智能进行重定向映射?
在过去的一年里,“AI”一词已经与“ChatGPT”混为一谈,因此从一开始就要明确一点,我们并不是在谈论使用基于生成 AI/LLM 的系统来进行重定向映射。
虽然 ChatGPT 之类的工具可以帮助您完成某些任务,例如为重定向逻辑编写棘手的正则表达式,但可能导致幻觉的生成元素可能会给我们带来准确性问题。
使用人工智能进行重定向映射的优势
速度
使用人工智能进行重定向映射的主要优势在于速度极快。几分钟内即可生成 10,000 个 URL 的初始映射,几个小时内即可进行人工审核。如果一个人手动完成此过程,通常需要几天的时间。
可扩展性
使用 AI 帮助映射重定向是一种可以在包含 100 个或超过 1,000,000 个 URL 的网站上使用的方法。大型网站也往往更具程序化或模板化,因此使用这些工具可以更准确地进行相似性匹配。
效率
对于较大的站点,多人的工作可由具有正确知识的单人轻松处理,从而腾出同事来协助迁移的其他部分。
准确性
虽然自动化方法会使一些重定向“错误”,但根据我的经验,重定向的整体准确性更高,因为输出可以指定匹配的相似性,为人工审核人员提供指导,让他们知道最需要关注的地方
使用人工智能进行重定向映射的缺点
过度依赖
使用自动化工具会让人自满,过度依赖输出。对于如此重要的任务,总是需要人工审核。
训练
脚本是预先编写的,流程很简单。然而,对于许多人来说,这将是全新的体验,而像 Google Colab 这样的环境可能会令人生畏。
输出方差
虽然输出是确定性的,但模型在某些网站上的表现会比其他网站更好。有时,输出可能包含“愚蠢”的错误,这些错误对于人类来说很明显,但对于机器来说更难发现。
使用 AI 进行 URL 映射的分步指南
在此过程结束时,我们的目标是通过将我们实时网站上的原始 URL 映射到我们暂存(新)网站上的目标 URL,来生成一个列出“来自”和“到”URL 的电子表格。
对于此示例,为了简单起见,我们将仅映射我们的 HTML 页面,而不是 CSS 或图像等其他资产,尽管这也是可能的。
- Screaming Frog 网站爬虫:Screaming Frog 是一个强大而灵活的网站爬虫,我们可以用它来收集匹配所需的 URL 和相关元数据。
- Google Colab:一种使用 Jupyter 笔记本环境的免费云服务,允许您直接从浏览器运行多种语言,而无需在本地安装任何东西。我们将使用 Google Colab 运行 Python 脚本来执行 URL 匹配。
- 用于站点迁移的自动重定向匹配器:我们将在 Colab 中运行Daniel Emery编写的 Python 脚本
步骤 1:使用 Screaming Frog 爬取你的实时网站
您需要对您的网站执行标准抓取。根据您网站的构建方式,这可能需要或不需要JavaScript 抓取。目标是生成尽可能多的可访问网站页面列表。
<img class="wp-image-437796 entered exited" src="data:;base64,” alt=”使用 Screaming Frog 爬取你的实时网站” width=”1264″ height=”586″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2024/02/Crawl-your-live-website-with-Screaming-Frog.png.webp 1264w,https://searchengineland.com/wp-content/seloads/2024/02/Crawl-your-live-website-with-Screaming-Frog-600×278.png.webp 600w,https://searchengineland.com/wp-content/seloads/2024/02/Crawl-your-live-website-with-Screaming-Frog-800×371.png.webp 800w,https://searchengineland.com/wp-content/seloads/2024/02/Crawl-your-live-website-with-Screaming-Frog-200×93.png.webp 200w,https://searchengineland.com/wp-content/seloads/2024/02/Crawl-your-live-website-with-Screaming-Frog-768×356.png.webp 768w” data-lazy-sizes=”(max-width: 1264px) 100vw, 1264px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2024/02/Crawl-your-live-website-with-Screaming-Frog.png.webp” />
步骤 2:导出带有 200 状态代码的 HTML 页面
一旦爬取完成,我们希望导出所有找到的带有 200 状态代码的 HTML URL。
首先,我们需要在左上角的下拉菜单中选择“HTML”。
<img class="wp-image-437797 entered exited" src="data:;base64,” alt=”尖叫的青蛙 – 突出显示 – HTML 过滤器” width=”580″ height=”282″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2024/02/Screaming-Frog-Highlighted-HTML-filter.png.webp 580w,https://searchengineland.com/wp-content/seloads/2024/02/Screaming-Frog-Highlighted-HTML-filter-200×97.png.webp 200w” data-lazy-sizes=”(max-width: 580px) 100vw, 580px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2024/02/Screaming-Frog-Highlighted-HTML-filter.png.webp” />
接下来,单击右上角的滑块过滤器图标并创建一个包含 200 的状态代码过滤器。
<img class="wp-image-437798 entered exited" src="data:;base64,” alt=”突出显示:自定义过滤器选项” width=”1002″ height=”366″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2024/02/Highlighted-Custom-filter-options.png.webp 1002w,https://searchengineland.com/wp-content/seloads/2024/02/Highlighted-Custom-filter-options-600×219.png.webp 600w,https://searchengineland.com/wp-content/seloads/2024/02/Highlighted-Custom-filter-options-800×292.png.webp 800w,https://searchengineland.com/wp-content/seloads/2024/02/Highlighted-Custom-filter-options-200×73.png.webp 200w,https://searchengineland.com/wp-content/seloads/2024/02/Highlighted-Custom-filter-options-768×281.png.webp 768w” data-lazy-sizes=”(max-width: 1002px) 100vw, 1002px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2024/02/Highlighted-Custom-filter-options.png.webp” />
最后,单击“导出”将数据保存为 CSV。
<img class="wp-image-437799 entered exited" src="data:;base64,” alt=”突出显示:导出按钮” width=”521″ height=”263″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2024/02/Highlighted-Export-button.png.webp 521w,https://searchengineland.com/wp-content/seloads/2024/02/Highlighted-Export-button-200×101.png.webp 200w” data-lazy-sizes=”(max-width: 521px) 100vw, 521px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2024/02/Highlighted-Export-button.png.webp” />
这将为您提供我们当前活动的 URL 列表以及 Screaming Frog 收集的所有默认元数据,例如标题和标题标签。将此文件另存为origin.csv。
重要提示:您的完整迁移计划需要考虑现有 301 重定向和可能为您的网站带来流量但无法通过初始抓取访问的 URL 等因素。本指南仅用于演示此 URL 映射过程的一部分,并非详尽指南。
步骤 3:针对您的临时网站重复步骤 1 和 2
我们现在需要从我们的登台网站收集相同的数据,以便我们可以进行比较。
根据您的登台网站的安全方式,您可能需要使用诸如Screaming Frog 的表单身份验证等功能(如果受密码保护)。
爬取完成后,您应该导出数据并将此文件保存为destination.csv。
可选:查找并替换您的临时网站域名或子域名,以匹配您的实际网站
您的临时网站可能位于不同的子域、TLD 或甚至与我们的实际目标 URL 不匹配的域上。因此,我将在我的 destination.csv 上使用“查找和替换”功能来更改路径以匹配最终的实时网站子域、域或 TLD。
例如:
- 我的实时网站是
https://withcandour.co.uk/(origin.csv)
- 我的暂存网站是
https://testing.withcandour.dev/(destination.csv)
- 该网站保留在同一域名上;它只是使用不同的 URL 进行重新设计,因此我将打开 destination.csv 并找到 的任何实例
https://testing.withcandour.dev并将其替换为https://withcandour.co.uk。
<img class="wp-image-437800 entered exited" src="data:;base64,” alt=”在 Excel 中查找和替换” width=”439″ height=”188″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2024/02/Find-and-Replace-in-Excel.png 439w,https://searchengineland.com/wp-content/seloads/2024/02/Find-and-Replace-in-Excel-200×86.png.webp 200w” data-lazy-sizes=”(max-width: 439px) 100vw, 439px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2024/02/Find-and-Replace-in-Excel.png” />
这也意味着当生成重定向映射时,输出是正确的,只需要编写最终的重定向逻辑。
步骤 4:运行 Google Colab Python 脚本
当您在浏览器中导航到脚本时,您会看到它被分成几个代码块,将鼠标悬停在每个代码块上都会出现一个“播放”图标。如果您希望一次执行一个代码块,则可以使用此功能。
但是,只需执行所有代码块,脚本就能完美运行,您可以通过转到“运行时”菜单并选择“全部运行”来执行此操作。
<img class="wp-image-437801 entered exited" src="data:;base64,” alt=”Google Colab 运行时” width=”699″ height=”499″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2024/02/Google-Colab-Runtime.png.webp 699w,https://searchengineland.com/wp-content/seloads/2024/02/Google-Colab-Runtime-473×338.png.webp 473w,https://searchengineland.com/wp-content/seloads/2024/02/Google-Colab-Runtime-158×113.png.webp 158w” data-lazy-sizes=”(max-width: 699px) 100vw, 699px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2024/02/Google-Colab-Runtime.png.webp” />
运行该脚本没有任何先决条件;它将创建一个云环境,并且在您的实例中第一次执行时,大约需要一分钟来安装所需的模块。
每个代码块完成后旁边都会有一个小的绿色勾号,但第三个代码块将需要您的输入才能继续,而且很容易错过,因为您可能需要向下滚动才能看到提示。
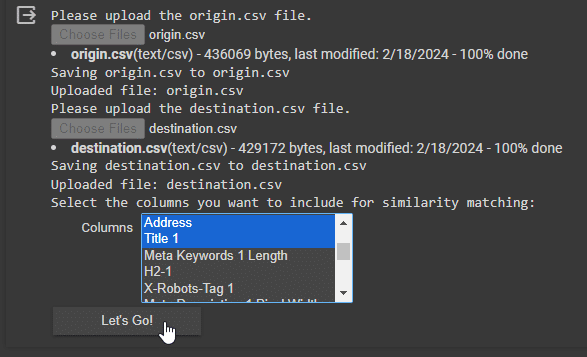
步骤 5:上传 origin.csv 和 destination.csv
出现提示时,单击“选择文件”并导航到您保存 origin.csv 文件的位置。选择此文件后,它将上传,并且系统将提示您对 destination.csv 执行相同操作。
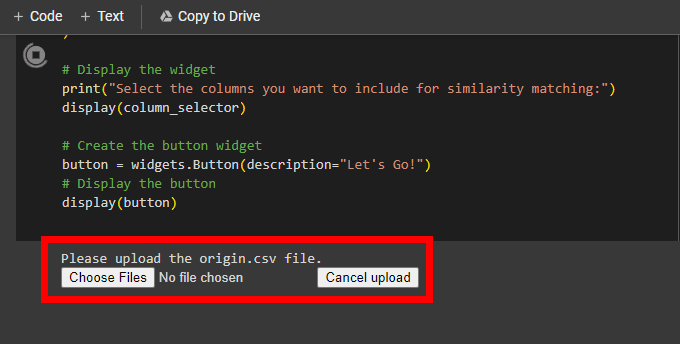
步骤 6:选择用于相似性匹配的字段
该脚本的强大之处在于它能够使用多组元数据集进行比较。
这意味着如果您处于移动 URL 地址不可比较的架构的情况,您可以对您控制的其他因素(例如页面标题或标题)运行相似度算法。
查看这两个网站,并尝试判断您认为哪些元素在它们之间保持相当一致。一般来说,如果您没有得到想要的结果,我建议从简单开始,然后添加更多字段。
在我的示例中,我们保留了类似的 URL 命名约定,尽管并不完全相同,并且在复制内容时我们的页面标题保持一致。
选择您要使用的元素并单击“开始吧!”
第 7 步:观看魔术
该脚本的主要组件是 all-MiniLM-L6-v2 和 FAISS,但它们是什么以及它们在做什么?
all-MiniLM-L6-v2 是 Microsoft MiniLM 系列模型中的一个小型高效模型,专为自然语言处理任务 (NLP) 而设计。MiniLM 会将我们提供的文本数据转换为能够捕捉其含义的数字向量。
然后,这些向量将启用相似性搜索,该搜索由 Facebook AI 相似性搜索 (FAISS) 执行,这是 Facebook AI Research 开发的用于高效相似性搜索和密集向量聚类的库。这将快速找到整个数据集中最相似的内容对。
步骤 7:下载 output.csv 并按相似度评分排序
output.csv 应该会自动从浏览器下载。打开后,应该有三列:origin_url、matched_url 和 similarity_score。
在您最喜欢的电子表格软件中,我建议按相似度分数进行排序。
<img class="wp-image-437806 entered exited" src="data:;base64,” alt=”Excel 按相似度分数排序” width=”584″ height=”266″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2024/02/Excel-Sort-by-similarity-score.png 584w,https://searchengineland.com/wp-content/seloads/2024/02/Excel-Sort-by-similarity-score-200×91.png.webp 200w” data-lazy-sizes=”(max-width: 584px) 100vw, 584px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2024/02/Excel-Sort-by-similarity-score.png” />
相似度得分可让您了解匹配程度。相似度得分为 1 表示完全匹配。
通过检查我的输出文件,我立即发现大约 95% 的 URL 的相似度得分超过 0.98,因此很有可能我节省了大量时间。
步骤 8:人工验证结果
请特别注意工作表上相似度分数最低的地方;这很可能是找不到良好匹配的地方。
在我的示例中,团队页面上有一些不太匹配的情况,这让我发现并非所有的团队资料都已在登台网站上创建——这是一个非常有用的发现。
该脚本还非常有帮助地为我们提供了针对旧博客内容的重定向建议,我们决定删除这些内容,而不将其包含在新网站上,但现在我们有一个建议的重定向,如果我们想将流量传递到相关的内容 – 这最终由您决定。
步骤 9:调整并重复
如果您没有得到想要的结果,我会再次检查您用于匹配的字段是否在各个站点之间尽可能保持一致。如果没有,请尝试不同的字段或字段组并重新运行。
未来将有更多人工智能
总的来说,我一直不愿意将任何人工智能(尤其是生成式人工智能)应用到重定向映射过程中,因为错误的代价可能很高,而且人工智能的错误有时很难发现。
然而,从我的测试中,我发现这些特定的 AI 模型对于这个特定的任务非常强大,并且它从根本上改变了我处理站点迁移的方式。
仍然需要人工检查和监督,但大部分工作节省的时间意味着您可以进行更彻底、更周到的人工干预,并比通常提前数小时完成任务。
在不久的将来,我预计我们将看到更具体的模型,这些模型将使我们能够采取额外的措施,包括提高下一步即重定向逻辑的速度和效率。